Giỏ hàng
0 Sản Phẩm


Trong giai đoạn AI chuyển từ thử nghiệm sang vận hành thực tế, bài toán không còn nằm ở việc “train model lớn đến đâu” mà là “triển khai và phục vụ người dùng nhanh đến mức nào”. Đây chính là nơi các GPU datacenter như NVIDIA A100 trở thành hạ tầng cốt lõi cho suy luận LLM (inference).
Khác với training, nơi chi phí có thể kiểm soát theo batch, inference là quá trình diễn ra liên tục, yêu cầu độ trễ thấp, khả năng mở rộng cao và tối ưu chi phí trên mỗi request. Trong bối cảnh đó, A100 là nền tảng giúp doanh nghiệp vận hành AI ở quy mô thực.
Cùng HQG tìm hiểu hiệu năng của GPU NVIDIA A100 cho các mô hình ngôn ngữ lớn hay còn được gọi là LLM (Large language Model)
NVIDIA A100 là GPU dành cho trung tâm dữ liệu, được xây dựng trên kiến trúc Ampere và thiết kế chuyên biệt cho các tác vụ AI, machine learning và high-performance computing.
Khác với GPU tiêu dùng, A100 tập trung vào khả năng xử lý song song quy mô lớn, với Tensor Core thế hệ thứ ba giúp tăng tốc các phép toán ma trận – nền tảng của deep learning. Phiên bản phổ biến nhất của A100 sở hữu 40GB hoặc 80GB bộ nhớ HBM2e, cùng băng thông gần 2 TB/s, cho phép xử lý khối lượng dữ liệu cực lớn trong thời gian ngắn.
Trong thực tế, A100 từng là tiêu chuẩn hạ tầng cho nhiều hệ thống AI lớn trên toàn cầu, đặc biệt trong giai đoạn bùng nổ của deep learning và các mô hình ngôn ngữ.
>>> Xem chi tiết tại NVIDIA A100 Tensor Core GPU: Tối Ưu AI Và HPC Ở Mọi Quy Mô
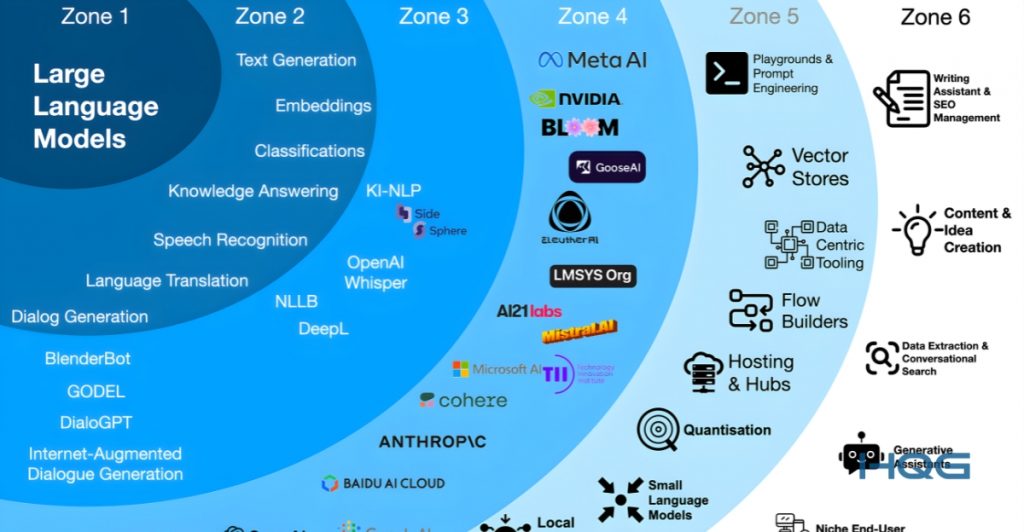
LLM (Large Language Model) là các mô hình AI được huấn luyện trên tập dữ liệu văn bản khổng lồ, có khả năng hiểu và sinh ngôn ngữ tự nhiên gần giống con người.
Các mô hình này thường có quy mô từ hàng tỷ đến hàng trăm tỷ tham số, ví dụ như GPT, BERT hay LLaMA. Với kích thước lớn như vậy, mỗi lần xử lý một câu hỏi đều yêu cầu thực hiện hàng tỷ phép tính liên quan đến ma trận và attention mechanism.
Điểm quan trọng của LLM không chỉ nằm ở khả năng trả lời, mà còn ở việc hiểu ngữ cảnh dài, sinh nội dung tự nhiên và thực hiện nhiều tác vụ như chatbot, tìm kiếm, phân tích dữ liệu. Tuy nhiên, chính quy mô lớn này khiến LLM trở thành một trong những workload nặng nhất trong lĩnh vực AI.
Sự phát triển của LLM gắn liền với sự tiến hóa của hạ tầng GPU. Các mô hình càng lớn, nhu cầu về compute, memory và bandwidth càng cao.
NVIDIA A100 đóng vai trò là nền tảng giúp hiện thực hóa LLM ở cả hai giai đoạn: Trong training, A100 cung cấp hiệu năng đủ để huấn luyện các mô hình hàng chục tỷ tham số trong thời gian hợp lý. Trong inference, GPU này giúp triển khai LLM với độ trễ thấp, phục vụ hàng nghìn người dùng đồng thời.
Đặc biệt, các công nghệ như Tensor Core, Mixed Precision và MIG giúp A100 tối ưu cả hiệu năng lẫn chi phí, biến việc triển khai LLM từ một bài toán nghiên cứu thành hệ thống có thể vận hành thực tế.
Suy luận LLM là quá trình mô hình đã được huấn luyện thực hiện dự đoán đầu ra dựa trên input người dùng. Với các mô hình từ 7B đến 70B tham số, mỗi request thực chất là hàng tỷ phép nhân ma trận diễn ra trong thời gian cực ngắn.
Một mô hình 13B tham số có thể yêu cầu hàng chục GB VRAM để chạy inference ổn định. Khi số lượng user tăng lên hàng nghìn hoặc hàng triệu request mỗi ngày, áp lực chuyển từ compute sang bandwidth và khả năng xử lý song song.
Trong thực tế triển khai, độ trễ (latency) chỉ cần tăng thêm vài trăm mili giây có thể làm giảm đáng kể trải nghiệm người dùng. Đây là lý do GPU như A100 được thiết kế không chỉ để mạnh, mà để xử lý hiệu quả những workload mang tính lặp lại và song song cực cao như LLM inference.
A100 được xây dựng trên kiến trúc Ampere với Tensor Core thế hệ 3, cho phép xử lý các phép toán matrix với hiệu suất vượt trội. Trong inference, các định dạng như FP16, BF16 và đặc biệt là INT8 đóng vai trò quan trọng trong việc giảm tài nguyên tiêu thụ.
A100 có thể đạt hiệu năng lên đến hàng trăm TFLOPS ở các precision thấp, giúp giảm đáng kể thời gian phản hồi của mô hình. Trong nhiều benchmark thực tế, inference BERT trên A100 có thể nhanh hơn hàng trăm lần so với CPU truyền thống.
Điều này mang lại một lợi thế rõ ràng: doanh nghiệp có thể phục vụ nhiều user hơn trên cùng một hạ tầng.
Một trong những điểm nghẽn lớn nhất khi triển khai LLM là memory bandwidth. Với 80GB HBM2e và băng thông gần 2 TB/s, A100 cho phép chạy các mô hình lớn hơn mà không cần chia nhỏ quá nhiều. Giảm độ trễ khi xử lý và tăng throughput cho các hệ thống inference real-time.
Trong thực tế, việc thiếu bandwidth thường khiến GPU không được sử dụng hết công suất. A100 giải quyết trực tiếp vấn đề này, giúp tối ưu hiệu năng thực thay vì chỉ hiệu năng lý thuyết.
>>> Xem thêm NVIDIA DGX A100: Hệ Thống Điện Toán Cho Mọi Tác Vụ AI
Một trong những công nghệ quan trọng nhất của A100 trong triển khai LLM là Multi-Instance GPU (MIG). Công nghệ này cho phép chia một GPU vật lý thành tối đa 7 instance độc lập.
Điều này có ý nghĩa rất lớn trong môi trường production. Thay vì dành toàn bộ GPU cho một model, doanh nghiệp có thể chạy nhiều model nhỏ hoặc nhiều phiên inference song song trên cùng một GPU.
Trong các hệ thống chatbot hoặc API AI, MIG giúp tăng mật độ workload trên mỗi GPU, từ đó giảm chi phí trên mỗi request. Đây là yếu tố then chốt khi xây dựng các dịch vụ AI có khả năng mở rộng.
A100 không hoạt động độc lập mà được thiết kế để scale trong các cluster lớn thông qua NVLink và NVSwitch. Điều này cho phép kết nối nhiều GPU thành một hệ thống thống nhất với độ trễ thấp.
Trong các hệ thống inference lớn, việc scale ngang là bắt buộc. Khi số lượng request tăng, hệ thống cần mở rộng mà không làm gián đoạn dịch vụ. A100 đáp ứng tốt yêu cầu này, đặc biệt trong các kiến trúc microservices hoặc AI platform.
Một số hệ thống lớn có thể sử dụng hàng trăm đến hàng nghìn GPU A100 để phục vụ inference cho hàng triệu người dùng mỗi ngày.
Nhìn chung, A100 vẫn là lựa chọn cân bằng giữa hiệu năng, độ ổn định và chi phí cho phần lớn hệ thống LLM hiện nay, đặc biệt trong môi trường doanh nghiệp.
| GPU | Kiến trúc | VRAM | Điểm mạnh | Phù hợp |
|---|---|---|---|---|
| NVIDIA A100 | Ampere | 40–80GB | Ổn định, phổ biến, tối ưu LLM | Production AI |
| NVIDIA H100 | Hopper | 80GB+ | Hiệu năng cao hơn A100 | LLM lớn, hyperscale |
| NVIDIA L40S | Ada | 48GB | Tối ưu inference, giá tốt | AI inference |
| NVIDIA RTX 4090 | Ada | 24GB | Giá rẻ, mạnh đơn lẻ | Dev, thử nghiệm |
>>> Xem thêm So sánh NVIDIA A100 40GB vs A100 80GB – chọn GPU nào?
Để đánh giá đúng hiệu năng của NVIDIA A100 trong suy luận LLM, cần dựa trên các benchmark độc lập và tài liệu kỹ thuật chính thức như MLPerf và NVIDIA developer. Những nguồn này phản ánh gần nhất hiệu năng trong môi trường thực tế, thay vì các tuyên bố marketing.
MLCommons là tổ chức đứng sau MLPerf – bộ benchmark được sử dụng rộng rãi bởi NVIDIA, Google, Intel và các hyperscaler để đo hiệu năng AI trong điều kiện gần production. Trong các bài thử nghiệm MLPerf Inference:
NVIDIA A100 đạt hiệu năng vượt trội so với CPU, với mức tăng tốc lên tới khoảng 200 lần trong các tác vụ NLP như BERT. GPU NVIDIA (bao gồm A100) liên tục dẫn đầu toàn bộ các hạng mục inference qua nhiều vòng benchmark. Các tối ưu phần mềm như TensorRT và sparsity tiếp tục cải thiện hiệu năng thêm từ khoảng 20% đến hơn 35% trong các bài test thực tế
Điểm quan trọng là MLPerf không đo trong điều kiện lý tưởng đơn lẻ, mà mô phỏng workload gần với production, bao gồm batch processing và xử lý liên tục. Điều này cho thấy A100 có khả năng duy trì hiệu năng ổn định khi triển khai thực tế.
Theo benchmark chính thức từ NVIDIA:
A100 có thể đạt hiệu năng inference nhanh hơn CPU tới khoảng 237 lần trong các tác vụ xử lý ngôn ngữ tự nhiên. Hiệu năng này đạt được khi kết hợp Tensor Core, mixed precision (FP16/BF16) và tối ưu bằng TensorRT
Ngoài ra, các cải tiến như structured sparsity giúp tăng thêm khoảng 20% throughput mà không cần thay đổi kiến trúc mô hình. Điều này xác nhận rằng GPU không chỉ nhanh hơn CPU, mà là nền tảng bắt buộc để triển khai LLM ở quy mô lớn.
Các nghiên cứu học thuật về Transformer inference cho thấy trong cấu hình tối ưu, latency có thể giảm xuống dưới 10 mili-giây cho mỗi truy vấn với các mô hình NLP cỡ nhỏ. Hiệu năng có thể nhanh hơn hàng chục lần so với CPU ngay cả khi không sử dụng cluster.
Tuy nhiên, cần phân biệt rõ Mức latency này áp dụng cho mô hình nhỏ hoặc trung bình (ví dụ BERT), không phải LLM hàng chục tỷ tham số. Với LLM lớn, latency sẽ cao hơn đáng kể và phụ thuộc vào batch size, tối ưu và kiến trúc hệ thống.
Trong triển khai thực tế, NVIDIA A100 không chỉ phục vụ một loại ứng dụng, mà được sử dụng rộng rãi trong nhiều ngành.
Về lĩnh vực thương mại điện tử, A100 được dùng để chạy hệ thống recommendation và tìm kiếm thông minh, giúp xử lý truy vấn người dùng theo thời gian thực với độ trễ thấp.
Trong tài chính, GPU này hỗ trợ các mô hình phân tích văn bản, phát hiện gian lận và chatbot tư vấn tự động, nơi yêu cầu xử lý dữ liệu nhanh và chính xác.
Truyền thông và marketing thì A100 được sử dụng để vận hành các hệ thống tạo nội dung AI, từ viết bài, tạo quảng cáo đến cá nhân hóa trải nghiệm người dùng.
Tại dịch vụ khách hàng, các chatbot LLM chạy trên A100 có thể xử lý hàng nghìn cuộc hội thoại đồng thời, giảm tải cho hệ thống support truyền thống.
Điểm chung của các use case này là yêu cầu inference liên tục, latency thấp và khả năng scale linh hoạt, những yếu tố mà A100 được thiết kế để đáp ứng.
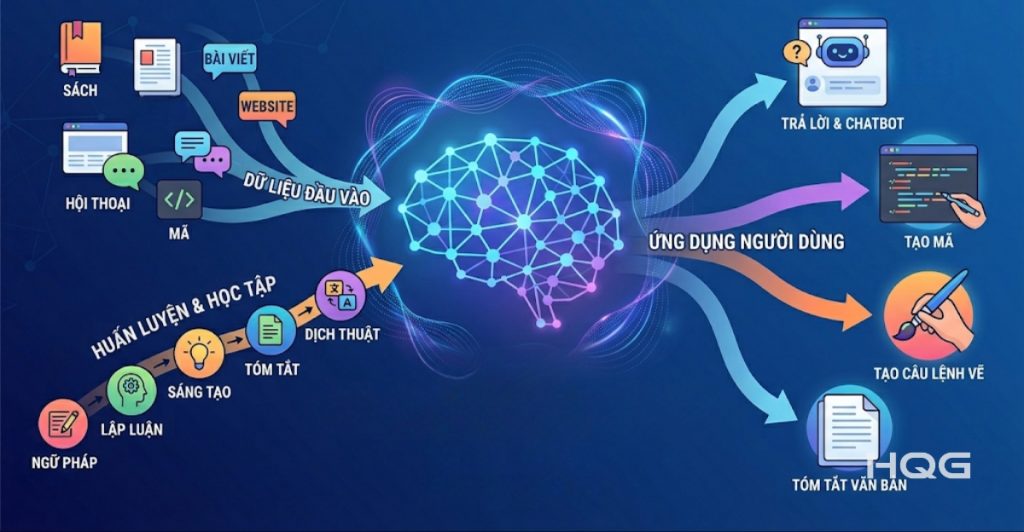
Hiệu năng của A100 không chỉ đến từ phần cứng mà phụ thuộc lớn vào hệ sinh thái phần mềm.
Theo các tài liệu từ NVIDIA:
– TensorRT có thể cải thiện hiệu năng inference end-to-end hơn 35% trong một số workload NLP
– Structured sparsity giúp tăng thêm khoảng 21% throughput
– Mixed precision (FP16/BF16/INT8) giúp giảm đáng kể thời gian xử lý và chi phí compute
Điều này cho thấy trong triển khai thực tế, việc tối ưu phần mềm có thể mang lại hiệu quả tương đương hoặc lớn hơn nâng cấp phần cứng.
Trong môi trường production, NVIDIA A100 thường không hoạt động độc lập mà nằm trong một kiến trúc gồm nhiều lớp. Một pipeline phổ biến bao gồm load balancer ở phía trước, hệ thống API xử lý request, lớp inference server (TensorRT, Triton) và cụm GPU A100 phía sau.
Với các mô hình LLM từ 7B đến 13B, một GPU A100 40GB hoặc 80GB có thể triển khai inference ổn định nếu được tối ưu batch và precision. Với mô hình lớn hơn như 30B–70B, hệ thống cần nhiều GPU chạy song song qua tensor parallel hoặc pipeline parallel.
Về chi phí, GPU A100 có giá thuê trên cloud dao động theo thị trường, nhưng điểm quan trọng nằm ở hiệu quả trên mỗi request. Trong nhiều benchmark, A100 có thể nhanh hơn CPU hơn 200 lần, đồng nghĩa với việc chi phí trên mỗi inference thực tế thấp hơn khi hệ thống đạt đủ tải.
ROI của A100 đến từ khả năng:
Giảm thời gian phản hồi, tăng trải nghiệm người dùng
Tăng throughput, phục vụ nhiều user hơn trên cùng hạ tầng
Giảm chi phí trên mỗi request khi scale
A100 phù hợp khi hệ thống đã vượt qua giai đoạn thử nghiệm và bắt đầu cần xử lý tải thực tế. Khi số lượng request tăng, việc sử dụng CPU hoặc GPU consumer sẽ nhanh chóng gặp giới hạn về hiệu năng và độ ổn định.
Trong các trường hợp cần phục vụ nhiều người dùng đồng thời, tối ưu chi phí dài hạn và đảm bảo latency ổn định, A100 trở thành lựa chọn hợp lý hơn so với các giải pháp rẻ hơn nhưng khó scale.
Trong thực tế, A100 không chỉ phục vụ một bước trong pipeline AI mà đóng vai trò xuyên suốt.
Ở giai đoạn training, A100 giúp xây dựng và fine-tune mô hình. Khi chuyển sang production, chính GPU này tiếp tục đảm nhiệm inference với hiệu suất cao.
Điều này giúp doanh nghiệp không cần thay đổi toàn bộ hạ tầng khi chuyển từ nghiên cứu sang triển khai. Sự đồng nhất này giảm đáng kể chi phí vận hành và độ phức tạp hệ thống.
Không phải mọi workload AI đều cần đến A100. Tuy nhiên, trong các trường hợp sau, A100 gần như là lựa chọn tiêu chuẩn cho:
– Triển khai LLM từ 7B tham số trở lên
– Xử lý hàng nghìn request đồng thời
– Yêu cầu latency thấp cho chatbot hoặc AI real-time
– Tối ưu chi phí trên mỗi inference ở quy mô lớn
Đối với các startup nhỏ hoặc workload nhẹ, A100 có thể là dư thừa. Nhưng khi hệ thống bắt đầu scale, việc chuyển sang GPU datacenter như A100 gần như là bước tất yếu.
Nếu doanh nghiệp đang cần đưa LLM vào vận hành thực tế, việc lựa chọn hạ tầng phù hợp sẽ quyết định trực tiếp đến hiệu năng và chi phí. Dịch vụ Cloud GPU và Server GPU từ HQG giúp rút ngắn thời gian triển khai, tối ưu chi phí đầu tư ban đầu và dễ dàng mở rộng khi hệ thống tăng tải.
Với các cấu hình NVIDIA A100 sẵn sàng, doanh nghiệp có thể triển khai inference LLM ổn định, đảm bảo latency thấp và hiệu suất cao ngay từ đầu, thay vì phải xây dựng hạ tầng phức tạp.
A100 vẫn được sử dụng rộng rãi trong các hệ thống AI production, ngay cả khi các thế hệ GPU mới hơn đã xuất hiện. Trong bối cảnh AI đang trở thành một phần cốt lõi của doanh nghiệp, hạ tầng không còn là chi phí mà là lợi thế cạnh tranh.
A100 cho phép doanh nghiệp:
– Triển khai AI nhanh hơn
– Tối ưu chi phí vận hành
– Mở rộng hệ thống linh hoạt
– Đảm bảo trải nghiệm người dùng ổn định
Suy luận LLM là nơi AI tạo ra giá trị thực, và cũng là nơi đòi hỏi hạ tầng mạnh nhất. NVIDIA A100 không chỉ đáp ứng yêu cầu về hiệu năng, mà còn giải quyết bài toán chi phí, khả năng mở rộng và vận hành lâu dài.
Đối với doanh nghiệp triển khai AI ở quy mô thực tế, A100 không còn là lựa chọn nâng cao, mà là nền tảng cần thiết để biến LLM từ công nghệ thành sản phẩm.
Nếu bạn đang tìm giải pháp GPU tối ưu chi phí cho các mô hình ngôn ngữ lớn LLM, việc lựa chọn đúng hạ tầng sẽ quyết định trực tiếp đến hiệu quả vận hành lâu dài.
>>> Liên hệ HQG để được tư vấn chi tiết về giải pháp GPU, báo giá và kiến trúc hệ thống phù hợp với nhu cầu thực tế.





