Giỏ hàng
0 Sản Phẩm


chọn NVIDIA A100 40GB hay 80GB? Cả hai đều thuộc cùng một kiến trúc Ampere, cùng nền tảng Tensor Core và khả năng mở rộng mạnh mẽ, nhưng mức giá và hiệu quả đầu tư lại có sự chênh lệch đáng kể.
Thực tế cho thấy, việc lựa chọn không nằm ở “GPU nào mạnh hơn”, mà nằm ở việc GPU nào phù hợp với workload và giai đoạn phát triển của hệ thống. Hiểu rõ sự khác biệt giữa hai phiên bản sẽ giúp doanh nghiệp tránh lãng phí tài nguyên hoặc gặp bottleneck trong tương lai.
NVIDIA A100 là GPU chuyên dụng cho datacenter, thuộc kiến trúc Ampere, được thiết kế để xử lý các workload nặng như AI training, inference, HPC và phân tích dữ liệu lớn. Khác với GPU dành cho máy tính cá nhân, A100 không phục vụ hiển thị mà tập trung hoàn toàn vào khả năng tính toán và vận hành ổn định trong môi trường server.
Điểm cốt lõi của A100 nằm ở việc kết hợp Tensor Core thế hệ thứ ba với các định dạng như TF32, FP16, BF16 và INT8, cho phép tăng tốc các tác vụ AI lên nhiều lần so với CPU hoặc GPU thế hệ trước. Trong nhiều bài toán thực tế, A100 có thể rút ngắn thời gian training từ hàng giờ xuống còn vài phút khi triển khai trên hệ thống nhiều GPU.
Ngoài hiệu năng, A100 còn được thiết kế như một phần của hạ tầng tính toán hoàn chỉnh. GPU này hỗ trợ công nghệ Multi-Instance GPU (MIG) để chia nhỏ tài nguyên cho nhiều workload, đồng thời sử dụng NVLink để kết nối nhiều GPU thành một cụm với băng thông cao, phục vụ các mô hình AI quy mô lớn.
Với khả năng xử lý mạnh, bộ nhớ lớn và khả năng mở rộng linh hoạt, NVIDIA A100 trở thành một trong những tiêu chuẩn quan trọng trong hạ tầng AI và datacenter hiện đại.

| Thông số | A100 40GB | A100 80GB |
|---|---|---|
| Kiến trúc | Ampere (GA100) | Ampere (GA100) |
| CUDA Cores | 6,912 | 6,912 |
| Tensor Cores | 432 (thế hệ 3) | 432 (thế hệ 3) |
| FP32 | 19.5 TFLOPS | 19.5 TFLOPS |
| TF32 | 156 TFLOPS | 156 – 312 TFLOPS |
| FP16 / BF16 | 312 TFLOPS | 312 – 624 TFLOPS |
| INT8 | 624 TOPS | 624 – 1248 TOPS |
| Bộ nhớ GPU | 40GB HBM2 | 80GB HBM2e |
| Băng thông bộ nhớ | ~1,555 GB/s | ~1,935 – 2,039 GB/s |
| TDP | ~250W (PCIe) / 400W (SXM) | ~300W (PCIe) / 400W+ (SXM) |
| MIG | Tối đa 7 instance (~5GB mỗi instance) | Tối đa 7 instance (~10GB mỗi instance) |
| NVLink | 600 GB/s | 600 GB/s |
| PCIe | Gen4 – 64 GB/s | Gen4 – 64 GB/s |
| Form factor | PCIe / SXM | PCIe / SXM |
NVIDIA A100 40GB và NVIDIA A100 80GB đều sử dụng GPU GA100 trên tiến trình 7nm, sở hữu 6912 CUDA cores và Tensor Core thế hệ thứ ba. Về lý thuyết, hiệu năng compute giữa hai phiên bản gần như tương đương.
Cả hai đều đạt khoảng 19.5 TFLOPS FP32, 156 TFLOPS TF32 trên PCIe và có thể lên đến 312 TFLOPS trên phiên bản SXM khi kết hợp sparsity. Điều này có nghĩa là nếu chỉ xét về khả năng tính toán thuần, sự khác biệt giữa hai phiên bản gần như không đáng kể.
Tuy nhiên, điểm tạo ra khoảng cách lớn nằm ở bộ nhớ và băng thông, đây cũng chính là yếu tố quyết định hiệu năng thực tế trong AI.
Phiên bản 40GB sử dụng HBM2 với băng thông khoảng 1.6TB/s, trong khi phiên bản 80GB sử dụng HBM2e với băng thông vượt 2TB/s. Không chỉ tăng gấp đôi dung lượng VRAM, A100 80GB còn cải thiện đáng kể tốc độ truy xuất dữ liệu.
Trong các mô hình AI hiện đại, đặc biệt là NLP và LLM, bộ nhớ thường là yếu tố giới hạn chứ không phải compute. Khi mô hình không thể fit vào VRAM, hệ thống buộc phải chia nhỏ batch hoặc sử dụng kỹ thuật offload, làm giảm hiệu năng tổng thể.
Trong nhiều benchmark thực tế, A100 80GB có thể đạt throughput cao hơn từ 2 đến 3 lần so với bản 40GB khi xử lý các mô hình lớn, đơn giản vì có thể giữ nhiều dữ liệu hơn trong bộ nhớ và tăng batch size.
Cả hai phiên bản đều hỗ trợ Multi-Instance GPU, cho phép chia GPU thành tối đa 7 instance độc lập. Tuy nhiên, sự khác biệt nằm ở dung lượng mỗi instance.
Với A100 40GB, mỗi instance chỉ khoảng 5GB VRAM, trong khi A100 80GB có thể cung cấp khoảng 10GB cho mỗi instance. Điều này ảnh hưởng trực tiếp đến khả năng triển khai cloud GPU và multi-tenant.
Trong môi trường cloud, A100 80GB cho phép chạy nhiều workload phức tạp hơn trên mỗi instance, trong khi A100 40GB phù hợp hơn với các tác vụ nhẹ hoặc inference.
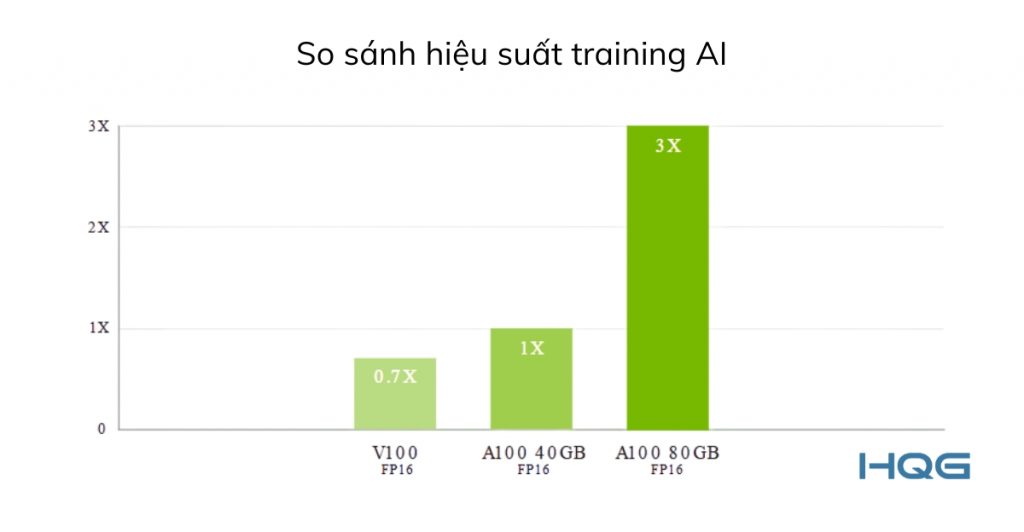
Trong các hệ thống training quy mô lớn, A100 80GB cho thấy lợi thế rõ rệt. Một mô hình như BERT có thể được huấn luyện trong thời gian dưới một phút khi sử dụng cluster hàng nghìn GPU A100, và phiên bản 80GB giúp tối ưu hiệu năng tốt hơn nhờ khả năng scale batch.
Ở inference, cả hai phiên bản đều vượt trội so với CPU, với hiệu năng cao hơn hàng chục đến hàng trăm lần. Tuy nhiên, với các mô hình lớn hoặc hệ thống yêu cầu độ trễ thấp, phiên bản 80GB vẫn có lợi thế nhờ khả năng xử lý dữ liệu lớn hơn trong mỗi lần tính toán.
Một trong những yếu tố quan trọng nhất khi lựa chọn GPU là chi phí. A100 80GB thường có giá cao hơn đáng kể, có thể chênh lệch từ vài nghìn đến hàng chục nghìn USD mỗi GPU tùy thời điểm.
Tuy nhiên, nếu xét trên hiệu quả dài hạn, chi phí này không đơn thuần là “đắt hơn”, mà là “đầu tư cho khả năng mở rộng”. Với các hệ thống AI phát triển nhanh, việc thiếu bộ nhớ sẽ dẫn đến phải nâng cấp toàn bộ hạ tầng, gây tốn kém hơn nhiều so với việc chọn đúng ngay từ đầu.
Ngược lại, nếu workload không yêu cầu bộ nhớ lớn, việc sử dụng A100 80GB có thể gây lãng phí tài nguyên.
A100 40GB phù hợp với các hệ thống đã ổn định về workload và không yêu cầu bộ nhớ lớn. Trong nhiều doanh nghiệp, GPU này vẫn đủ để xử lý AI inference, mô hình machine learning truyền thống và các pipeline dữ liệu.
Ngoài ra, trong môi trường cloud hoặc multi-tenant với workload nhẹ, A100 40GB giúp tối ưu chi phí tốt hơn mà vẫn đảm bảo hiệu năng.
A100 80GB trở thành lựa chọn gần như bắt buộc khi làm việc với các mô hình lớn, đặc biệt là LLM, deep learning quy mô lớn hoặc các hệ thống cần batch size cao.
Trong các hệ thống training hiện đại, bộ nhớ không chỉ ảnh hưởng đến tốc độ mà còn quyết định việc có thể triển khai hay không. Nếu mô hình không thể chạy trên 40GB, việc nâng cấp lên 80GB là giải pháp trực tiếp và hiệu quả nhất.
Ngoài ra, với các hệ thống cần scale lâu dài, A100 80GB giúp giảm rủi ro phải thay đổi kiến trúc trong tương lai.
Trong thực tế triển khai, nhiều hệ thống bắt đầu với A100 40GB để tối ưu chi phí, sau đó chuyển sang 80GB khi workload tăng. Điều này cho thấy hai phiên bản không cạnh tranh trực tiếp mà bổ sung cho nhau trong các giai đoạn khác nhau.
Các doanh nghiệp lớn thường ưu tiên A100 80GB ngay từ đầu để tránh bottleneck, trong khi các startup hoặc hệ thống thử nghiệm thường chọn 40GB để giảm chi phí ban đầu.
Câu trả lời phụ thuộc hoàn toàn vào nhu cầu. Nếu hệ thống hướng đến AI quy mô lớn, cần xử lý mô hình phức tạp và mở rộng lâu dài, A100 80GB là khoản đầu tư hợp lý và mang lại hiệu quả cao.
Ngược lại, nếu workload ở mức vừa phải và cần tối ưu chi phí, A100 40GB vẫn là lựa chọn cân bằng giữa hiệu năng và ngân sách.
Điểm quan trọng không nằm ở việc chọn GPU mạnh nhất, mà là chọn GPU phù hợp nhất với chiến lược phát triển hạ tầng.
HQG cung cấp giải pháp GPU server, Cloud GPU và hạ tầng AI với cả NVIDIA A100 40GB và 80GB, giúp doanh nghiệp lựa chọn cấu hình phù hợp và triển khai nhanh chóng.
>>> Liên hệ HQG để được tư vấn chi tiết về giải pháp GPU, báo giá và kiến trúc hệ thống phù hợp với nhu cầu thực tế.
Nhà cung cấp Máy chủ, thiết bị lưu trữ IBM, Dell, HPE và các linh kiện, phụ kiện; Dịch vụ IT Outsource, cho thuê thiết bị, nâng cấp, bảo trì hệ thống – Giải pháp CNTT toàn diện.
Website: https://hqg.vn/
Fanpage: Facebook | LinkedIn | YouTube | TikTok
Hotline: 0922 999 111 | Email: info@hqg.vn
Trụ sở: 8 Nguyễn Duy, Phường Gia Định, TP. Hồ Chí Minh, Việt Nam.
VPGD Hồ Chí Minh: Lô O, số 10, Đ.15, KDC Miếu Nổi, Phường Gia Định, TP. Hồ Chí Minh.
VPGD Đà Nẵng: 30 Nguyễn Hữu Thọ, Phường Hải Châu, Đà Nẵng.
VPGD Hà Nội: 132 Vũ Phạm Hàm, Phường Yên Hoà, Hà Nội.





