Giỏ hàng
0 Sản Phẩm


Tối ưu hiệu suất khi chạy mô hình AI trên Cloud GPU là một trong những yêu cầu quan trọng nhất đối với doanh nghiệp, kỹ sư và các nhóm phát triển hệ thống AI.
Hiệu suất không chỉ liên quan đến tốc độ xử lý, mà còn ảnh hưởng trực tiếp đến chi phí, độ ổn định và khả năng mở rộng của hệ thống. Dù nền tảng Cloud GPU mang lại sức mạnh tính toán lớn, hiệu suất thực tế vẫn phụ thuộc vào cách tổ chức pipeline, sử dụng phần mềm và lựa chọn phần cứng phù hợp.
Bài viết dưới đây tổng hợp những phương pháp quan trọng và dễ áp dụng nhất để tăng hiệu suất khi chạy mô hình AI trên Cloud GPU, dựa trên kỹ thuật phổ biến trong công nghiệp và các tối ưu đã được kiểm chứng.
Chạy mô hình AI trên Cloud GPU là cách mà doanh nghiệp hoặc lập trình viên sử dụng máy chủ GPU được đặt trên hạ tầng đám mây (Cloud) để huấn luyện hoặc vận hành các mô hình trí tuệ nhân tạo, thay vì phải mua một GPU vật lý đặt tại văn phòng.
Hình dung đơn giản như thuê “sức mạnh xử lý” từ xa: bạn không cần sở hữu phần cứng, chỉ cần mở trình duyệt hoặc API, chọn loại GPU muốn dùng (như NVIDIA A100, H100…), và bắt đầu chạy mô hình.
Pipeline dữ liệu (data pipeline): Chuỗi xử lý dữ liệu từ input đến GPU; tối ưu để GPU luôn chạy liên tục.
Inference (suy luận): Dùng mô hình đã huấn luyện để tạo đầu ra như ảnh, văn bản hay dự đoán dữ liệu.
Profiling: Đo lường hiệu suất để tìm điểm nghẽn GPU, CPU hay pipeline dữ liệu.
Mixed Precision (FP16/BF16): Giảm độ chính xác tính toán để tăng tốc và tiết kiệm bộ nhớ GPU.
Batch size: Số mẫu dữ liệu xử lý cùng lúc trên GPU; ảnh hưởng tốc độ và bộ nhớ.
Quantization (INT8/INT4): Giảm độ chính xác mô hình để tăng tốc inference, giảm chi phí GPU.
KV Cache: Bộ nhớ đệm trong mô hình ngôn ngữ lớn, giảm độ trễ khi sinh từng token.
Khi triển khai mô hình AI trên Cloud GPU, ba yếu tố chính quyết định tốc độ và khả năng tận dụng tài nguyên: Phần cứng GPU, Bộ công cụ phần mềm và framework và pipeline dữ liệu (chuỗi xử lý dữ liệu từ input đến GPU) và kiến trúc hệ thống.
GPU chỉ có thể đạt hiệu suất tối đa khi CPU, bộ nhớ, lưu trữ và mạng truyền đều hoạt động đồng bộ. Đây là lý do tốc độ thực tế đôi khi thấp hơn nhiều so với thông số lý thuyết.
Khi chạy AI (nhất là deep learning), bạn cần rất nhiều phép tính ma trận. GPU sinh ra để xử lý song song cực nhanh, nên tốc độ cao hơn CPU rất nhiều. Nếu mua GPU vật lý, chi phí sẽ lớn. Nền tảng Cloud GPU giải quyết vấn đề này bằng cách cung cấp GPU từ xa, cho phép bạn bật/tắt theo nhu cầu, tính phí theo giờ.
>>> Có thể bạn quan tâm: Generative AI – trí tuệ nhân tạo sinh là gì? Chứng minh thực tế
– Huấn luyện (training) mô hình như GPT, BERT, YOLO, Stable Diffusion.
– Suy luận (inference) để tạo đầu ra như ảnh, văn bản, phân loại dữ liệu.
– Tinh chỉnh (fine-tuning) mô hình lớn theo dữ liệu riêng của doanh nghiệp.
– Chạy batch processing hoặc xử lý AI backend cho ứng dụng.
– Không phải đầu tư phần cứng đắt đỏ.
– Linh hoạt nâng cấp hoặc đổi GPU mạnh hơn khi cần.
– Quy mô mở rộng gần như không giới hạn (có thể dùng nhiều GPU cùng lúc).
– Truy cập dễ dàng từ bất kỳ đâu.
Cách tăng hiệu suất khi chạy mô hình AI trên Cloud GPU bao gồm lựa chọn GPU và kiến trúc phù hợp với workload, tối ưu phần mềm và pipeline dữ liệu, áp dụng huấn luyện phân tán cho mô hình lớn, cải thiện hiệu suất inference, đồng thời đo lường và profiling để phát hiện và khắc phục các điểm nghẽn.
Mỗi loại GPU được thiết kế cho những nhu cầu khác nhau. Việc lựa chọn sai phần cứng dẫn đến chi phí cao mà hiệu suất không cải thiện.
Với mô hình Transformer hoặc deep learning quy mô lớn: A100, H100 phù hợp nhờ Tensor Cores mạnh cho FP16/BF16. Với inference hoặc workload tầm trung: T4 hoặc L4 là lựa chọn tối ưu chi phí. Còn lại, với bài toán nhiều GPU thì nên ưu tiên hạ tầng có NVLink hoặc mạng tốc độ cao để tránh nghẽn băng thông.
Cloud GPU không chỉ là sức mạnh của GPU; nó còn bao gồm dung lượng RAM, tốc độ NVMe và băng thông mạng. Việc đánh giá nhu cầu toàn hệ thống giúp đảm bảo hiệu suất ổn định trong suốt quá trình huấn luyện hoặc triển khai.

Tối ưu phần mềm thường đem lại mức tăng hiệu suất lớn hơn so với việc nâng cấp phần cứng. Một số kỹ thuật tiêu chuẩn bao gồm:
Giảm độ chính xác có kiểm soát giúp tăng tốc độ huấn luyện, giảm chi phí bộ nhớ và tận dụng tối đa Tensor Cores trên GPU.
Giảm lượng bộ nhớ dành cho activation bằng cách tính toán lại một phần trong backward pass. Kỹ thuật này cho phép chạy batch size lớn hơn mà không cần tăng GPU.
PyTorch: sử dụng torch.compile, FSDP, hoặc DeepSpeed.
TensorFlow: bật XLA để tối ưu biểu đồ tính toán.
Mô hình lớn: Megatron-LM hoặc DeepSpeed ZeRO giúp phân tán tham số và optimizer hiệu quả.
Những cải tiến này thường không yêu cầu thay đổi kiến trúc mô hình, giúp tăng tốc độ với chi phí tối thiểu.
>>> Xem thêm Tất Tần Tật về Nvidia H100: hiệu năng, ứng dụng và lợi ích
Nhiều trường hợp GPU không chạy hết công suất vì pipeline dữ liệu quá chậm, do đó tối ưu dữ liệu là bước thiết yếu để giữ GPU hoạt động liên tục. Khi pipeline dữ liệu được tối ưu, mức sử dụng GPU thường tăng rõ rệt từ 50–60% lên gần tối đa.
DataLoader (PyTorch): Việc tăng số lượng worker, bật pin_memory, prefetch dữ liệu và sử dụng batch có kích thước hợp lý giúp cải thiện throughput.
tf.data (TensorFlow): Có thể tối ưu pipeline bằng prefetch song song, batching, cache dữ liệu và sử dụng map với num_parallel_calls=AUTOTUNE.
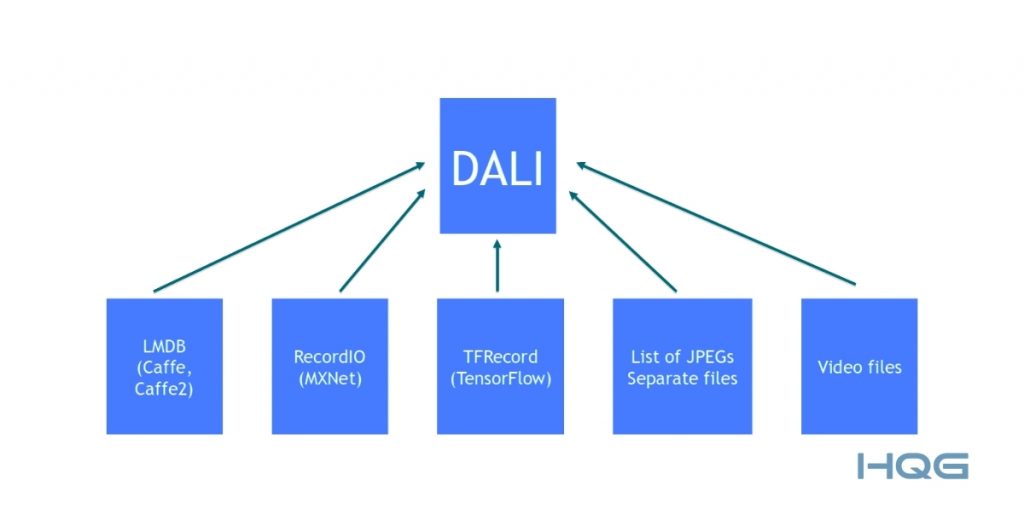
Dùng NVIDIA DALI: DALI hỗ trợ chuyển toàn bộ pipeline tiền xử lý lên GPU, giảm tải cho CPU và tăng tốc đáng kể, đặc biệt trong các tác vụ xử lý ảnh và video.
Tối ưu lưu trữ và truy xuất dữ liệu: Ưu tiên ổ NVMe thay vì HDD, tránh lưu dữ liệu trên storage mạng có độ trễ cao, và chia shard dữ liệu khi phân tán nhiều node.
Khi mô hình hoặc dữ liệu quá lớn, huấn luyện phân tán trên nhiều GPU hoặc nhiều node là lựa chọn cần thiết. Hiệu suất của phương pháp này phụ thuộc chủ yếu vào cách các GPU giao tiếp và đồng bộ với nhau.
Các kỹ thuật như Data Parallelism, Tensor Parallelism và Pipeline Parallelism giúp chia nhỏ mô hình hoặc dữ liệu để tận dụng tối đa tài nguyên. Công cụ như DeepSpeed và Megatron-LM hỗ trợ giảm tải bộ nhớ, tối ưu truyền dữ liệu và cải thiện khả năng mở rộng khi chạy trên nhiều GPU.
Bên cạnh đó, hạ tầng mạng tốc độ cao — gồm kết nối 100–200 Gbps, InfiniBand hoặc NVLink — là yếu tố quan trọng để giảm độ trễ và duy trì tốc độ đồng bộ gradient.
Huấn luyện phân tán chỉ đạt hiệu quả tối ưu khi cả GPU, phần mềm và đường truyền đều đáp ứng yêu cầu của mô hình.
>>> Xem thêm NVIDIA NVLink là gì? Cách hoạt động và ứng dụng thực tế
Inference là giai đoạn quan trọng nhất đối với sản phẩm AI triển khai thực tế. Tối ưu tốt giúp giảm chi phí hạ tầng và tăng tốc phản hồi.
– Tối ưu biểu đồ tính toán
– Hợp nhất kernel
– Hỗ trợ FP16 và INT8
– Giảm dung lượng mô hình
– Hỗ trợ batching động
– Tốc độ phục vụ cao
– Tích hợp nhiều framework cùng lúc
– Thích hợp cho hệ thống có lượng request lớn
Giảm độ chính xác có kiểm soát để tăng tốc độ và giảm chi phí GPU mà không ảnh hưởng nhiều đến chất lượng mô hình.
Giúp giảm độ trễ trong quá trình sinh từng token. Tối ưu inference thường giúp giảm đến 30–70% chi phí vận hành, đặc biệt trong hệ thống phục vụ hàng triệu yêu cầu mỗi ngày.
Không thể tối ưu hiệu quả nếu không đo lường đầy đủ, vì profiling là cách duy nhất để biết chính xác hệ thống đang bị chậm ở đâu. Các công cụ như PyTorch Profiler, TensorBoard, Nsight Systems, nvidia-smi dmon hoặc các công cụ tracing trên CPU giúp phân tích chi tiết quá trình huấn luyện và vận hành mô hình.
Thông qua profiling, bạn có thể xác định liệu GPU đang idle, CPU bị quá tải, data loader xử lý chậm hay băng thông mạng không đủ. Dựa trên số liệu thực tế luôn mang lại kết quả tối ưu hơn nhiều so với việc chỉnh sửa theo phỏng đoán.
Tăng hiệu suất khi chạy mô hình AI trên Cloud GPU là quá trình tối ưu toàn diện gồm phần cứng, phần mềm và pipeline dữ liệu. Sử dụng GPU mạnh không đảm bảo tốc độ cao nếu pipeline bị tắc nghẽn hoặc mô hình chưa tận dụng đúng kỹ thuật tối ưu.
Khi áp dụng đồng thời nhiều phương pháp — từ chọn GPU phù hợp, bật mixed precision, tối ưu dữ liệu cho đến profiling chi tiết — hệ thống AI có thể đạt hiệu suất gần với mức tối đa mà Cloud GPU cung cấp.
Việc tối ưu hiệu suất không chỉ giảm thời gian huấn luyện và tăng tốc inference, mà còn giúp doanh nghiệp tiết kiệm chi phí, mở rộng quy mô và triển khai AI một cách bền vững hơn.
>>> Có thể bạn quan tâm Dell PowerEdge XE9780 và XE9785 ra mắt – Server AI thế hệ mới
Cloud GPU HQG mang đến hạ tầng GPU hiệu năng cao dành cho doanh nghiệp và đội ngũ phát triển AI tại Việt Nam. Hệ thống sử dụng GPU thế hệ mới, kết nối mạng tốc độ cao và storage NVMe, giúp huấn luyện mô hình lớn, tăng tốc inference và triển khai AI ở quy mô sản xuất một cách ổn định.
Với khả năng mở rộng linh hoạt, chi phí tối ưu và đội ngũ hỗ trợ kỹ thuật sát sao, Cloud GPU HQG là nền tảng đáng tin cậy để doanh nghiệp khai thác tối đa sức mạnh tính toán và rút ngắn thời gian đưa sản phẩm AI ra thị trường.
Liên hệ HQG ngay để được tư vấn giải pháp Cloud GPU, Server AI / GPU hiện đại nhất.
Website: https://hqg.vn/
Fanpage: Facebook | LinkedIn | YouTube | TikTok
Hotline: 0922 999 111 | Email: info@hqg.vn
Trụ sở: 8 Nguyễn Duy, Phường Gia Định, TP. Hồ Chí Minh, Việt Nam.
VPGD Hồ Chí Minh: Lô O, số 10, Đ.15, KDC Miếu Nổi, Phường Gia Định, TP. Hồ Chí Minh.
VPGD Đà Nẵng: 30 Nguyễn Hữu Thọ, Phường Hải Châu, Đà Nẵng.
VPGD Hà Nội: 132 Vũ Phạm Hàm, Phường Yên Hoà, Hà Nội.





